
SRC Innovations has successfully run a Product Catalogue Search Engine as a SaaS solution for a number of years now. It serves a range of Australian clients, serving search traffic using a mix of modern ML as well as classical AI methods.
I’d attribute part of our success to our use of the Google Cloud Platform (GCP) and it’s Google Kubernetes Engine (GKE) simply because it is very nicely integrated, whilst at the same time giving us the flexibility that is so desired where cloud deployments are concerned.
In this blog, I’m going to give a quick overview of our stack so you can see how we’re benefiting from GCP and their cloud platform.
The Srchy stack
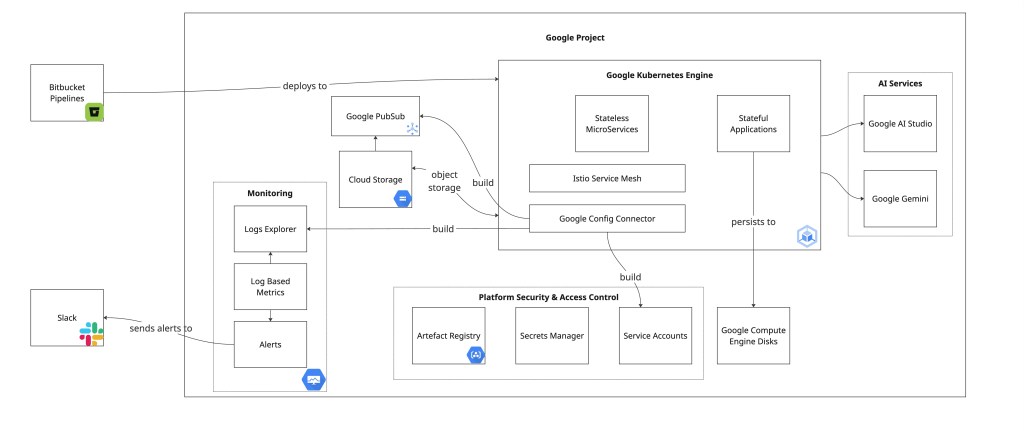
The bulk of Srchy’s services – both stateless microservices & stateful applications – sit within Google Kubernetes Engine. Over the years, within those GKE clusters, we have run:
- various Java based stateful search engines – backed by GCE’s “Balanced drives” for a mix of cost effectiveness and “good enough” disk IO
- MongoDb servers
- at least 2 RNN based Neural Network (mapped to a node with an attached GPU – of course)
- about 45 (currently) different microservices mostly using NodeJS
- several – more recent – LLM powered services
- a lot of batch jobs
- and one of my favourites… GCP’s Config Connector
All of these sit on a stack of GCE nodes underneath, efficiently sharing CPU + Memory resources during quiet times, and then scaling additional nodes when things get busy, and more instances are required so more compute resources are available.
About Config Connector
Config Connector is Google’s answer to “can we get a kubernetes based declarative mechanism to build GCP resources?”
In short, it lets you define GCP resources by using YAML from within a GKE cluster. If you’re already using Kubernetes, then you’d be very well versed in the approach, and you’ll appreciate how it works.
| Config Connector | Terraform | gcloud CLI |
| Only runs in kubernetes cluster, and only for GCP resources | Multi cloud, can be run from a dev laptop or a pipeline. Needs a hosted solution for sharing state | GCP resources only, can be run from a dev laptop or a pipeline. |
| Constantly reconciles the state of GCP resources against the YAML definition of the resource. | Assessing resource drift happens on a triggered command | No mechanism to assess resource drift. |
| Declarative – eventually consistent | Imperative, but with a mechanism to recover from drift | Purely imperative. Once there is a divergence, there is no mechanism for recovery without an edit or rebuild of the drifted resource. |
Below I provide two sample Config Connector manifests. These are actually part of our Helm charts ensuring that our microservices that may rely on things like Storage Buckets and their associated storage notification events can be co-deployed together, ensuring that their dependencies are met as per the good practices espoused by full stack Infrastructure As Code principles.
apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageBucket
metadata:
annotations:
cnrm.cloud.google.com/force-destroy: "false"
labels:
helm.sh/chart: catalog-import-extract-monitor-0.1.17
meta.srchy.ai/app: catalog-import-extract-monitor
meta.srchy.ai/client: srchy
meta.srchy.ai/client-env: prod
meta.srchy.ai/client-brand: srchy
app.kubernetes.io/name: catalog-import-extract-monitor
app.kubernetes.io/instance: demo
app.kubernetes.io/version: "0.0.17"
app.kubernetes.io/managed-by: Helm
name: srchy-monitored-bucket
namespace: config-connector
spec:
location: australia-southeast1
storageClass: STANDARD
lifecycleRule:
- action:
type: SetStorageClass
storageClass: COLDLINE
condition:
age: 30
withState: ANYapiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageNotification
metadata:
name: srchy-monitored-bucket-0
namespace: config-connector
labels:
helm.sh/chart: catalog-import-extract-monitor-0.1.17
meta.srchy.ai/app: catalog-import-extract-monitor
meta.srchy.ai/client: srchy
meta.srchy.ai/client-env: prod
meta.srchy.ai/client-brand: srchy
app.kubernetes.io/name: catalog-import-extract-monitor
app.kubernetes.io/instance: demo
app.kubernetes.io/version: "0.0.17"
app.kubernetes.io/managed-by: Helm
spec:
bucketRef:
external: srchy-monitored-bucket
payloadFormat: JSON_API_V1
topicRef:
name: srchy-monitored-bucket-topic
objectNamePrefix: upload/
eventTypes:
- "OBJECT_FINALIZE"As you can see above, the storage bucket has – as part of its manifest declared a storage class of coldline after 30 days, and the Storage Notification even specifies the objectNamePrefix.
We have found this to be a significantly easier and more repeatable manner of deploying GCO resources.
About Google’s AI Services – Gemini & AI Studio
Google’s Gemini is acknowledged as a capable LLM and drives many systems – including OpenText’s own Aviator platform – and its API integrations with the rest of the Google ecosystem is pretty sweet. It’s AI Studio is also a very nice piece of developer kit, and makes it really easy to explore the quality of LLM prompts across different models at the same time.
This isn’t the right place for a full run down of Google’s AI services compared to others providers, but I do have some quick comments based on our experiences. The way that Google has integrated access to AI systems of all types – both modern neural network styles, as well as classical models – and made the necessary hardware also available via standard VMs and also via GKE is pretty impressive, and should make it a good pick for anybody who is interested in deploying AI at scale in this modern world.
Other GCP Resources
Before you decide that we only use GKE, I’ll also touch now on the other GCP resources.
Cloud Storage Object Buckets
Because, let’s face it, are there any cloud based implementations out there that haven’t benefited from cheap and plentiful object storage?
PubSub
GCP actually has a comprehensive and fully-managed PubSub offering in a single service that provides the typically desired message queueing, streaming, and pub-sub functionalities desired for eventing use cases.
This is – especially from an architecture and developer perspective – neater than some other cloud platforms’ combinations of 2 services to achieve almost the same thing.
We use it to – as mentioned above – identify when clients have provided their latest product catalogues so that we can ingest and run our ML workloads across them for search-related product enrichment before shipping them to our search engines.
Platform Security & Access Control – i.e. Artefact Registry, Secrets Management, and Service Accounts!
As you may have inferred, we run fairly swish DevOps pipelines, which includes a bunch of deployment pipelines. This means that we know we need to have stable deployment packages, without secrets committed to git, and with using service accounts that have really tightly controlled IAM policies.
Service Accounts & their associated IAM policies are all quite feasible as well via the Config Connector resources. We’ve had to do a nice little script separately to bridge the “We have a secret, how do we get it into Secrets Manager AND into Kubernetes” gap, but otherwise, Config Connector continues to be a good way to declaratively define GCP resources.
Observability – i.e. Logs Explorer, Log Based Metrics, and Alerts
You may have noticed that we use Istio as a service mesh in our clusters. This has made it very easy for us to set up our microservices to output access logs, which GKE then easily ingests into its Logs Explorer suite. We can then set up Log Based metrics so we can monitor things like HTTP traffic to our services, as well as other metrics. On top of that, we can turn GCP’s log based metrics into alerts based on thresholds, and have them integrated with Slack and our other alerting routing systems!
GCP also have a very nice query language for their Logs Explorer where it is straightforward for anybody to pick up and quickly understand how it works. This is a far cry from other logging solutions where their DQL tends to require a bit of effort to fully comprehend.
Observability – GKE Dashboards
I really want to give a special callout to GCP on how brilliant their out-of-the-box GKE dashboards are. We initially used a lot of prometheus + grafana, but we dropped most of it when GCP released their OOTB GKE dashboards as they give you everything you could ever need. Pod and node resource usage, filtered by namespaces, and even better, interactive playbooks about how to investigate and resolve cluster problems!
The Wrap Up
In a complex and varied landscape of multiple cloud providers, Google’s GCP has proven its functional strength and reliable infrastructure, combining to make our lives easy.
Their AI offerings especially from within their Cloud are superbly developer friendly and effective, streamlining our innovation without compromising depth.
For us as a consulting and product company, these efficiencies mean we can focus on delivering business value and engaging with the technical details that matter, rather than being slowed down by unnecessary hurdles.
Put simply: we like GCP, we’ll continue to trust it as part of our multi-cloud mix, and we’ll keep turning to it when it makes sense!
If you had questions about GCP, GKE, or how Google’s AI offerings can help your business drive real business value quickly, please reach out at https://www.srcinnovations.com.au/contact.